
Every risk decision you makeis only as good as the data behind it.
Thousands of sources. Dozens of formats. Different languages, schemas, and update schedules. The world's risk data was never built to work together — until now.
The data problem is not one you solve once. It is one you solve every single day.
The Problem
A world of disconnected data
Risk intelligence doesn't fail because it's hard to read. It fails because the data underneath it was never built to connect. Sources that don't know about each other. Formats that can't speak to each other. Updates on different cycles. Governed by different standards. In different languages.
Siloed by design
Watchlist data. Adverse media. Corporate registries. Court records. Each built independently, with no intention of ever connecting to the others.
Different languages
Structured SQL. Unstructured web text. Government XML. PDFs. Each source speaks a different data language — with no shared schema, identifier, or format.
Out of sync
Each source updates on its own schedule. A risk surfacing today may not appear in your tools until tomorrow — or next week. Regulators don't wait.
The In-House Trap
Companies try to solve this themselves.
Most are still trying.
Building a proprietary data intelligence layer sounds logical — until you encounter the true scale of what it requires. The organisations that have tried know: this is not a data pipeline problem. It is a decade-long infrastructure challenge.
Years, not months.
In-house data projects rarely finish. Regulatory requirements shift. Sources go dark. Maintenance never ends.
Far more than it looks.
Data licensing. AI engineers. Legal review. Infrastructure. The hidden costs dwarf the build — and most discover this too late.
Permanent blind spots.
No team covers 15,000+ sources across 200 jurisdictions. In compliance, the source you're missing is the one that matters.
Our Answer
From raw data to actionable intelligence
We don't just aggregate data. We ingest it, normalise it, resolve identities across sources, enrich it with context, and synthesise it into intelligence your compliance team can act on — and your auditors can defend.
01
Raw Data Ingestion
15,000+ sources
02
Normalisation
One unified language
03
Entity Resolution
AI cross-matching
04
Enrichment
Context layered
05
AI Synthesis
Risk signals surfaced
06
Intelligence
Audit-ready output
AI-Powered Intelligence
Connecting what can't be connected
Aggregation is easy. Anyone can pull a list. The hard problem — the one that actually protects your organisation — is determining that “J. Smith, Board Member, ABC (Pty) Ltd” and “John Andrew Smith, Director, ABC Holdings International” are the same person. Our AI resolves this at scale, across thousands of sources, in milliseconds.
Cross-Source Deduplication
Matching across registries with no shared identifiers.
Transliteration & Alias Resolution
Name variants, Cyrillic, aliases — caught every time.
Quantified Confidence Scoring
Every match scored, not binary — defensible in audit.
The Scale
The infrastructure behind every decision
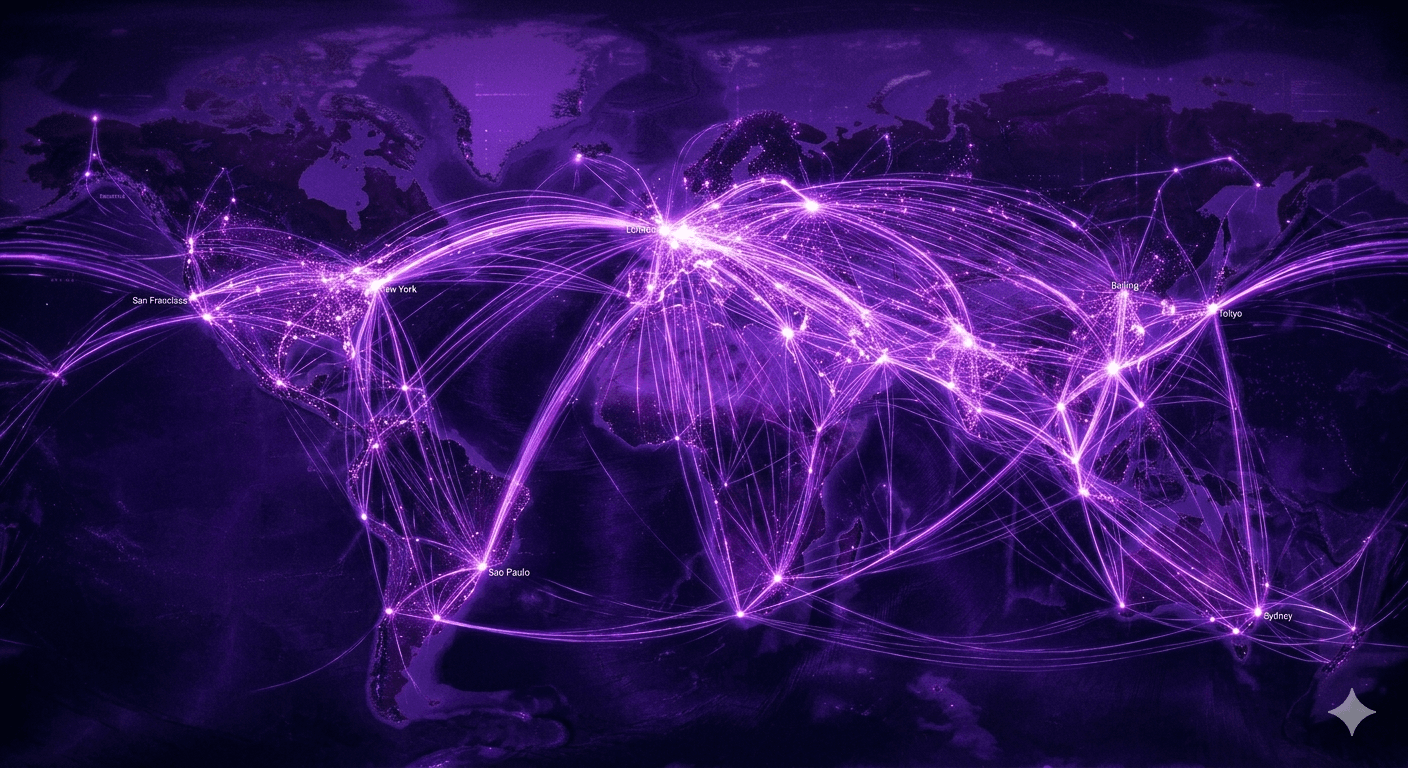
Global Intelligence Sources
Across watchlists, registries, unstructured media, courts & ESG data
Countries & Jurisdictions
Screening Databases
Risk Categories Monitored
Compliance Professionals
What We Monitor
Across every dimension of risk
Eight distinct source categories — each continuously monitored, normalised, and enriched by our intelligence infrastructure.
Watchlist & Screening Databases
OFAC, UN Security Council, EU, UK HMT/OFSI, AUSTRAC, INTERPOL and 44+ more databases — continuously updated across all major jurisdictions.
PEP Registers & Political Exposure
Global and regional PEP registries covering heads of state, government officials, and their immediate associates.
Corporate Registries & Ownership
Company registration, beneficial ownership structures, and directorship records from official registries across 200+ jurisdictions.
Unstructured Media & Adverse Content
Tens of millions of articles, reports, and publications — parsed, deduplicated, and scored for credibility and relevance across languages and regions.
Court Records & Litigation
Civil and criminal court filings, judgments, and ongoing litigation from global legal databases and official court records.
ESG & Governance Data
Environmental controversies, social violations, and governance failures from international ESG ratings and investigative reporting.
Regulatory Enforcement Actions
Fines, debarments, and enforcement filings from regulators across FATF member states and beyond.
Government & Official Databases
Official blacklists, debarment registers, and enforcement actions from government authorities across 200+ jurisdictions.
Global Reach
200+ countries.
Zero blind spots.
From major financial centres to high-risk corridors — with particular depth across the FATF grey-list landscape and emerging-market jurisdictions where off-the-shelf solutions consistently fall short.
Always Current
Data that never
stops updating.
A risk that emerged this morning should appear in your next screening — not in next month's batch update. Our infrastructure runs continuous ingestion cycles so your intelligence reflects the current state of the world, not yesterday's snapshot.
Continuous ingestion
Sources polled on rolling cycles, not scheduled batches
Near real-time updates
New risk signals surface within hours, not days
Historical depth
Full record retained for audit trails and trend analysis
Talk to an Expert
The world's most critical decisions
run on the right data.
Our data infrastructure took years to build and never stops evolving. Speak with one of our experts — no pitch, just clarity on what it means for your compliance programme.